OpenAI hosted a contest challenging participants to create the best agent for playing custom levels of the classic game Sonic the Hedgehog, without having access to those levels during development. The goal of this competition is to come up with a meta-learning algorithm that can transfer learning from a set of training levels to a set of previous unseen test levels. This is very interesting as most RL algorithms are tested in the same environment where they are trained, hence completely ignoring the important question whether the agent can be generalized to previously unseen environments.
Hoping to learn more about transfer learning in RL, I decided to take part in this contest and was able to create an agent that can play the custom levels reasonably well, snatching a 5th place finish with a score of 5522 out of 9000. In this blog post, I am going to go through my approach in detail. But before we dive in, let me say a few words about the meaning of meta-learning (or simply transfer learning) in the context of Reinforcement Learning.
1. Meta Learning in the context of RL
Human is capable of learning a new task very quickly by leveraging past experience. Our inborn intelligence allows us to recognize objects from very few examples and learn to complete a foreign task with very little experience. Ideally, we want our intelligent agent to also be able to do the same thing, using prior experience to pick up new skills more quickly. However, this is no easy task. In typical RL research, algorithms are tested in the same environment where they were trained, hence complex algorithms with many hyperparameters and good at memorization, but incapable of adapting to new situations, are flavored. In contrast, the goal of meta-learning is to train a model on a variety of learning tasks, such that it can solve new learning tasks more quickly using only a small number of training samples.
ImageNet Analogy. For those of you who have done image classification with deep neural nets before, we usually use a pretrained network trained on ImageNet and finetune the model on our own dataset to speed up training. Analogously, in the context of RL meta-learning, we want to have a “pretrained” agent trained on a variety of learning tasks and “finetune” our pretrained agent to adapt to our own tasks quickly.
If you want to dive deeper into the subject, OpenAI has introduced several well known meta-learning algorithms such MAML, RL^2, and Reptile etc, all showcasing great capability in adapting to new tasks from very few examples. I strongly encourage you to check them out and get a feeling of where the state of the art is at. Now, with a brief understanding of what meta-learning trying to achieve, let’s talk about the detail of the competition.
2. OpenAI Retro Competition
In this competition, we are given a training set of 58 levels drawn from 3 different games, Sonic the Hedgehog, Sonic the Hedgehog2, and Sonic 3 And Knuckles. Roughly speaking, the way to clear the levels is to figure out a route to move forward (i.e. to the right) and reach a predefined destination.



The reward consists of two components: a horizontal offset, and a completion bonus. The horizontal offset reward is normalized per level so that an agent’s total reward will be 9000 if it reaches the predefined horizontal offset that marks the end of the level. The completion bonus is 1000 for reaching the end of the level instantly, and drops linearly to zero at 4500 timesteps. This way, agents are encouraged to finish levels as fast as possible.
Our goal is to utilize these training levels to train a meta-learning model that can learn fast on a set of secret test levels. While we can train as much as we want in the training levels, training on secret levels are limited only to 1 million frames and 12 hours of wall-clock time (on OpenAI machines). Hence, we want to come up with a meta-learning fast learner that can leverage experience from training levels to learn fast on the secret levels, as illustrated in the diagram below:

Source: https://contest.openai.com/
Ranking for this competition is based on the average score on the secret test levels created by OpenAI. There are 2 sets of secret test levels. One set is for the public leaderboard and the other set is for determining the final winner.
3. OpenAI Baseline Implementations
OpenAI generously provided implementations of two well known RL algorithms Proximal Policy Optimization (PPO) and Rainbow specially tuned for this competition.
Of all the fancy RL algorithms that were introduced recently, PPO is particularly known for its stability, since under the hood it is optimizing a clipped surrogate loss function to refrain the policy from changing too much during each gradient update. As a result, multiple gradients updates per iteration are allowed which makes it not only more stable, but also more sample efficient than similar algorithms such as Advantage Actor Critic (A2C).
Rainbow, on the other hand, is a combination of a family of methods based on DQN, the famous RL algorithm which DeepMind introduced in 2015 to play Atari games from pixel inputs. It incorporates several state of the art methods such as Distribution Bellman, Prioritized Experience Replay, Noisy Network, Double DQN, Dueling, Multi-step Bootstraping into a single algorithm that works extremely well and set record benchmark in Atari. Generally speaking, the fact that it is off-policy makes it more sample efficient (theoretically speaking) than on-policy algorithms such as PPO. Hence, it is more suited to tackle problems with less training examples. On the flip side, as with other DQN methods, Rainbow comes with many hyperparameters so it is notoriously hard to tune and not as stable as PPO.
4. First Attempt: Set up Consistent Local Validation
As with many other ML competitions I took part before, the very first thing is to set up a local validation scheme that is consistent with the public leaderboard. First, I submitted the baseline PPO and Rainbow models to the leaderboard server for evaluation. I then set up a local validation scheme by splitting the 58 training levels into a training set of 47 levels and testing set of 11 levels as recommended by OpenAI. I found that the local validation set is slightly harder than the leaderboard test set but the score difference is generally consistent. With a 1 million frames hard limit, PPO scored around 3200 in the leaderboard and 2500 in local validation.
Next comes the fun part of this contest: to create a meta-learning fast learner using the training levels. I read OpenAI’s technical report and found out that joint training on the 47 training levels with PPO and utilize the joint model to initialize the weights of the PPO model for the leaderboard test set lead to a very good results. In comparison, the very same joint training method applies to Rainbow doesn’t work so well. Considering this and also the fact that Rainbow takes significantly more time to run (3 times slower than PPO), I decided to spend most of my time on PPO.
5. Joint training on multiple levels with PPO
Most RL problems involve training an agent to master only a single environment. The objective of joint training is to train a single agent that can master multiple environments (e.g. 47 training levels) simultaneously. There are several ways to conduct joint training on multiple levels. To speed up training, I decided to use a distributed training method with reference to Batched A2c based on OpenAI baselines implementation.
On a high level, given \(N\) environments (i.e. 47 training levels), I created N distributed workers to gather experiences (i.e. observations, actions, rewards, termination, etc) from each of the \(N\) levels for \(T\) number of timesteps respectively. The experiences are then aggregated and sent to the GPU to perform gradient updates via PPO algorithm.
In addition, I adopted several tricks to facilitate PPO training.
1) Action space
Of the 12 buttons ( B, A, MODE, START, UP, DOWN, LEFT, RIGHT, C, Y, X, Z ) available for the game, most of them are not useful. Hence I used only 8 button combinations as the action space ( {{}, {LEFT}, {RIGHT}, {LEFT, DOWN}, {RIGHT, DOWN}, {DOWN}, {DOWN, B}, {B}} ).
2) Reward scaling
I scaled the reward by multiplying it by a factor of 0.01. This is crucial to get PPO to work properly.
3) Large batch size
I used a very large batch size (>25,000) to perform the gradient updates. Empirically, I found that a large batch size (so long it fits into the memory of GPU) works better than a small batch size for joint training. This is probably due to the fact that with a small batch size only experiences from a small number of levels are presented for each gradient update, and that this will lead to severe bias in the gradient estimation.
I ran joint training for 200 million frames on a home machine with 12 cpus and a Nvidia 1080 GPU. The training curve is illustrated below, we can see that mean episode rewards improved steadily and settled at around 5000.
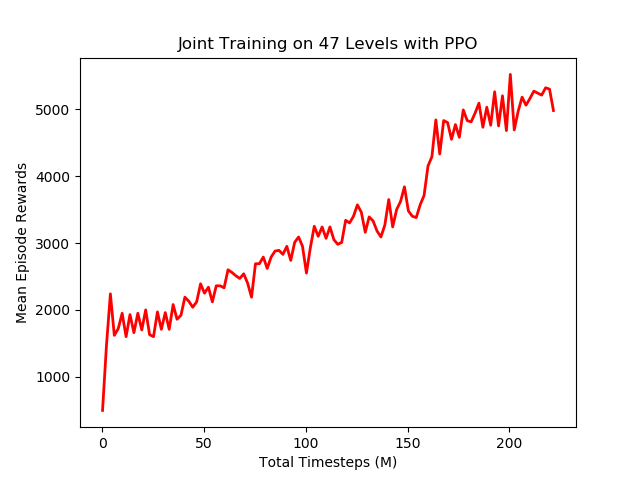
6. Transfer Learning with Joint Agent
I then utilize the agent joint trained on the 47 training levels as pretrained weights to initialize another PPO model for training on the secret test levels for leaderboard evaluation. I also added the following tricks to further improve agent performance:
1) Reward shaping
Sometimes the agent might get stuck in the middle of the level, and need to move backwards to explore an alternative route (illustrated below). A reward in the delta x (forward) direction will discourage the agent too heavily from exploring backwards. Instead, I used delta max(x) as the reward. This will encourage the agent to explore backwards if there is no way to advance head-on in the level.
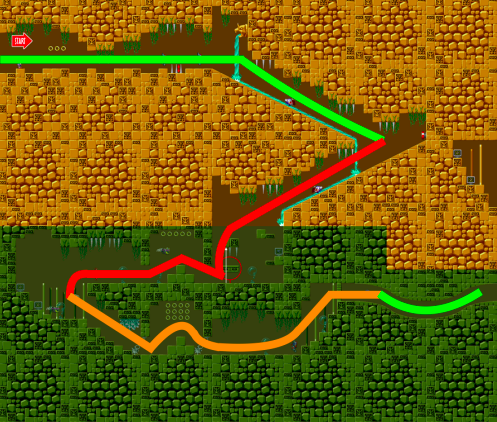
Source: https://arxiv.org/pdf/1804.03720.pdf
Notice that I did not apply this reward shaping trick during the joint training phase. Empirically I found that not including the the reward shaping trick at joint training phase would lead to a better validation score. I suspect that this is because backward exploration is very level specific, and that experience learned from backward exploration during joint training will more likely confuse the agent during test evaluation phase.
2) A smaller Entropy Constant
Since a pretrained model is used to jumpstart the training for test evaluation, a smaller entropy constant (for PPO loss function) of 0.001 is used so that the agent will better leverage experience from pretrained model.
Avoid Overfitting. To prevent the joint agent from overfitting to the training levels, I sampled several joint trained agents at various points of joint training and performed a cross validation analysis on the local validation levels. Below is the chart showing the training curve (on the local validation set) of several PPO models initialized by different joint agents sampled at various points during joint training. The sampled points are 2M, 6M, 20M, 60M, 100M, 130M, 170M, and 200M total timesteps. The training curve for PPO with no pretraining (bottom orange) is also included for comparison.
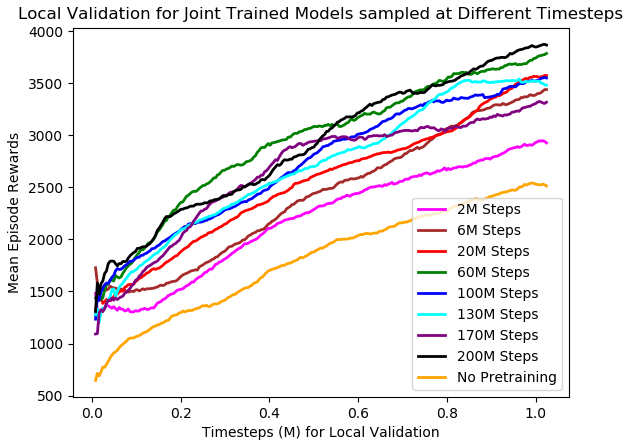
We notice that PPO agents initialized with pretrained models work a lot better than the PPO agent with no pretraining (bottom orange). However, the improvement in local validation score stopped after around 20M timesteps. Agents initialized by joint model trained beyond 20 million timesteps do not translate to improvement in local validation score. This is probably due to overfitting to the training sets. Hence, I simply picked the model from around 30 million timesteps to be the joint agent for initializing the PPO agent for the leaderboard test levels.
As expected, using joint agent trained on 47 pretrained levels to jumpstart PPO training significantly improve the leaderboard score. The leaderboard score improved from 3200 to above 4000 consistently. Though such improvement is well documented in OpenAI’s technical report, being able to replicate the results still brought a great level of satisfaction! But, despite the significant score improvement, there still exists a noticeable gap between my score and the top score of around 6000. Longing to resolve the difference, I subsequently made several failed attempts to boost score (to be covered below), but none of them worked.
At that moment, I took a step back and thought hard about possible ways to make the PPO agent learn faster. As discussed above, the 47 training levels were drawn from 3 different games (Sonic the HedgeHog, Sonic the HedgeHog2, and Sonic 3 And Knuckles). Although their high level rules are the same (i.e. discover a route to move forward and clear the level), many levels have distinctive “features” such as turf textures, character sprites, types of obstacles, and even types of available moves. For example the “Spindash” move ( {Down + B} ) is only available for Sonic the HedgeHog2, and Sonic 3 And Knuckles. I was wondering if we can leverage these information to make learning faster. It turns out that we can!
7. Use of “Expert” Pretrained Agents
As mentioned earlier, different levels have different characteristics, such turf textures, character sprites, types of obstacles, and types of available moves, etc. What if we can train a model that can identify such “features” from any given level and have a corresponding “expert” pretrained RL agent to jumpstart the PPO training for the test evaluation.
7.1 Group levels according to similarities
One way to achieve the first part is to group levels together according to their “similarities” and train a classifier that can take as inputs sampled frames from a given level and identify which “group” that level belongs to.
There are many ways to group levels together. For simplicity sake, I decided to group levels by their corresponding “zone”. For Sonic game, levels are organized into various zones, each zone has 1 to 3 “Acts”. Levels from the same zone share similar features such as turf, background image, characters, moves, obstacles, etc. There are a total of 27 zones in the training levels. I trained a ResNet50 classifier that takes as inputs random frames sampled from the level and output probabilities of the level belonging to a particular zone.
I created a training dataset using frames randomly sampled from the 47 training levels and trained a ResNet50 classifier using SGD optimizer with Nesterov acceleration. After 3 epochs of training, an accuracy of above 99% was achieved for the validation dataset. I have worked on several projects on image classification/object detection last year. I was so used to great results that I kind of took them for granted. Ironically, only after I started working on reinforcement learning projects did I realize how “great” those results truly are!
7.2 Expert Pretrained Agents
So now we have 27 groups each representing a unique zone. As discussed above, for each group, there should exist a corresponding “expert” agent that is specifically designed to learn fast on levels from that group. One way to train such “expert” agent is to take the joint agent discussed above in section 5 and further “finetune” it (i.e. joint train it) only on the levels it is specializing in. Also, I applied the same transfer learning tricks discussed in section 6 to train the expert agents. One last thing, to avoid overfitting, I only finetuned the joint agent for 1 million total timesteps. This way, the resulting expert agent is able to retain the experience learned from joint training on the training levels while having the capability to learn fast on levels drawn from the specialized level group. In a sense, such procedure is equivalent to allowing the PPO agent to train beyond the 1 million frame limit imposed at the test evaluation stage (i.e. improving data efficiency).
Below is a diagram of a sample workflow of the final algorithm on a test/evaluation level:

For a particular test/evaluation level \(L\), the algorithm first sample \(N\) frames from the level, feed them into the ResNet50 classifier to classify the level into one of the 27 groups by majority vote. Then assign the corresponding expert pretrained agent to initialize the weights of the PPO agent to be trained on level \(L\).
It took quite some time to train the individual expert agents. After the training is done, I made a submission with this algorithm, the leaderboard score jumped to 5525 and that translated to a 5th place finish!!!
I want to close out this section with several thoughts about this method:
1) I only got to try this approach a few days before the competition ends, hence did not have the time to fully figure out the optimal number of iterations for training the expert agents. That said, there are rooms to cross validate and further optimize the above procedure.
2) There might be better ways to group together levels other than by “zone”. For example, levels across different zones can share similar “themes” such as “ancient ruins”, “underwater”, “industrial”, “lava”, “tropical island”, and “jungle”, etc. Such theme labels are available on the Sonic game official site. We could train a classifier to classify levels according to themes, which might lead to better results compared to grouping by zones.
3) I see the method above to have some kind of resemblence to hierarchical Reinforcement Learning in the sense that there is a “master” policy controlling a group of “sub policies”. Here, I use a ResNet classifier to represent the “master” and zone specific expert models to represent the “sub policies”. For the sake of Sonic, I defined the master and expert networks manually as opposed hierarchical RL where the master and sub policies are chained together and trained in an end-to-end fashion. If I have more time, I would definitely love to try out the full fledge hierarchical RL approach and see if it works for this problem.
8. Other Approaches I tried but did not work
1) PPO with curiosity driven exploration
Curiosity driven exploration is an approach with the goal of encouraging the RL agent to explore novel states when the environment only provides sparse reward signal. For Sonic, I thought it would be helpful in cases where the agent got stuck in the middle of the level and in need of discovering new routes to bypass the hard to get through obstacles. I incorporated curiosity driven exploration into PPO to make several submissions. However, there was no noticeable improvement in score so I abandoned it.
2) Joint Training for Rainbow agent
As covered in previous sections, using a joint training model to jumpstart PPO training on test levels greatly improve its performance. We would expect the same thing to happen to Rainbow. To test that out, I trained a joint Rainbow agent on the 47 training levels with distributed training for 2 million total timesteps. I then used the joint agent to initialize the weights of the Rainbow agent and train it on the test levels. Out of my surprise, the score became significantly worse (from around 4000 without pretraining to around 2000).
I suspect that this is due to the fact that when we use joint Rainbow agent to initialize the weights, the experience replay buffer is predominantly filled with only “good” trajectories. As a result the training is severely biased towards a small subset of <state, action> pairs. To test out such hypothesis, I added epsilon greedy exploration to Rainbow. The score did improve significantly, but did not get to surpass that of the Rainbow model with no pretraining. Also considering the fact that experiment turnover time for Rainbow is too slow (3x slower than PPO), I decided not to proceed further with Rainbow but to focus on PPO for the rest of the contest.
9. Final Thoughts
1) Variance in Score
I noticed that there exists a huge variance in score for multiple submissions of the same agent on the same validation/test level. I’ve tried to make multiple submissions of the same algorithms to the leaderboard and observed that the variance in score can be as high as +/- 1000. This is in fact a known problem for reinforcement learning.
For example, when an agent is trained on a difficult level, if it is lucky enough to discover a secret route to bypass some hard to get through obstacles during the initial exploration phase, a good score will likely to follow. However, most of the time the agent would simply fixates on the most likely path and that would lead to only a mediocre score. This is unlike image classification where there exists a ground truth label for every training example, so that the model will likely converge to similar results if given enough time to train.
It’s not easy to think up ways to reduce such variance in score. It probably requires some kind of novel exploration schedules or use of human demonstration data to guide the initial exploration phase.
2) Without a prior model of the world, it’s hard to achieve human level performance
OpenAI’s technical report reported a benchmark of around 7300 scored by human subject with only a few hours of playing. In contrast, even with an unlimited amount of training time on the training levels, the top computer agent could only score around 6400 on the easier leaderboard test levels. This led me to believe that without a prior model of the world and the ability to make causal inference, artificial agent trained by RL can only go so far and is still far lacking human’s ability to generalize and learn from very few examples.
3) From a competition standpoint, go for the low hanging fruits first!!!
After the contest ended, I realized that a score of 6000 can be achieved simply by tuning 2 hyperparameters of the baseline Rainbow model, with no pretraining involved. The lesson to take is that for the sake of the competition always try to go for the low hanging fruits first. It’s not that hyperparameters tuning is easy but it is certainly more straightforward as compared to implementing more complex methods. And I am quite surprised that a well tuned Rainbow is capable of achieving such a high score. I did try to tune PPO hyperparameters (e.g. minibatch size, number of epochs, entropy constant, reward scaling factor, etc) but could not find a better combination than the default ones.
10. Acknowledgment
Last of all, I would love to thank OpenAI for organizing this amazing competition. It is a great opportunity for me to dive deep into the subject of meta-learning in RL. I would also like to thank fellow contestants who participated and shared their ideas in the forum. The source code I used for this competition can be found here.
If you have any questions or thoughts feel free to leave a comment below.
You can also follow me on Twitter at @flyyufelix.