I recently took part in the Kaggle State Farm Distracted Driver Competition. This is an image recognition problem which deep learning is particular good at solving. Hence by taking part in this competition I got the perfect opportunity to acquaint myself with the deep learning modeling pipeline, which typically entails data preprocessing, data augmentation, train/fine-tune Convolutional Neural Networks, and ensemble multiple models to obtain the final output.
I learned a lot in this competition and would love to share my approach and more importantly the lessons I learned.
Problem Statement
We are given a dataset of driver images taken by a camera mounted inside the car. Our goal is to predict the likelihood of what the driver is doing in each picture. There are 10 categories - safe driving, texting - right, talking on the phone - right, texting - left, talking on the phone - left, operating the radio, drinking, reaching behind, hair and makeup, talking to passenger. We are given 22,424 training samples and 79,726 testing samples. For each test image, our model has to assign a probability value on each of the 10 driving states.
Below are examples of training images with their corresponding labels:

The metric is multi-class cross entropy loss (also called logarithmic loss).
Our Approach
We set up a typical deep learning pipeline which includes data preprocessing, data augmentation, fine-tuning various pre-trained convnets models, and finally ensemble those models to obtain our final prediction for submission.

Data Preprocessing. We downsample the images from 640x480 to 224x224 so that the dimension is compatible to that required by the pre-trained Convnets we use for fine-tuning. Downsample input images is a common practice to ensure the model and the corresponding training samples (from a single mini-batch) can fit into the memory of the graphics card.
Data Augmentation. We double the size of the original dataset by performing random rotations and translations on each image sample. Training on the augmented dataset will make the resulting model more robust and less prone to overfitting.
Fine-tune pretrained Networks. This competition allows participants to use pre-trained networks trained on outside dataset. Hence, instead of training a Covnet from scratch, which was not going to give us a good result due to the small size of the dataset, we use pre-trained Covnets trained on ImageNet (1.2M labeled images).
We fine-tune several Convnet models, namely VGG16, VGG19, and GoogleNet (Inception) on both the original and augmented dataset. For each model, we truncate and replace the top layer (softmax layer with 1000 categories for ImageNet) with our new softmax layer with 10 categories each representing a driving state.
We use 5-fold cross validation (cv) and run stochastic gradient descent with back propagation. Our single model output is the geometric mean of 5 cv prediction vectors.
For a more comprehensive treatment of fine-tuning on pre-trained Deep Learning Models, you can reference this earlier post.
Semi-supervised Learning. The idea of semi-supervised learning is to train a base model, use the base model to get predictions on the test set, then use those predictions as labels and re-train on train and test set combined. In our case, we carry out semi-supervised learning on VGG16. This leads to a modest improvement in the leaderboard score.
Test Data Augmentation. During test time, we augment each test image by random rotation and translation, and average the prediction of each transformed version of the test image to obtain the final prediction on that image. This further improve our leaderboard score.
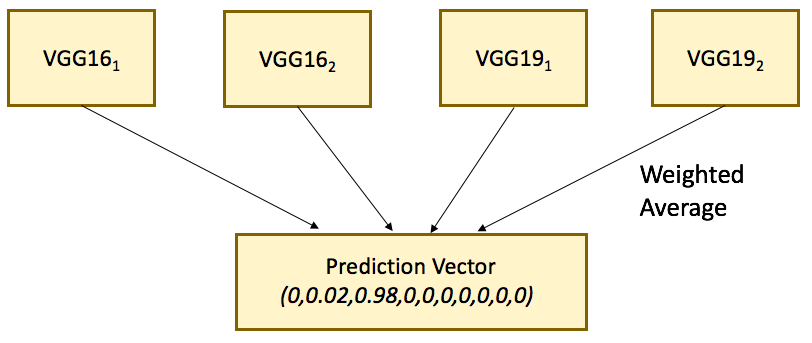
Model Ensemble. As with other Kaggle or predictive analytics competitions, the final submission is usually a blend of 2 or more different base models. We ensemble different models by weighted arithmetic mean. Our final prediction is the weighted average of 4 VGG models. We did not include Inception model GoogLeNet in the blend since it got us a worse public leaderboard score.
Final Result
At the end of the competition, our team achieved a final ranking of 17th out of 1450 (Top 2%) in the public leaderboard and 47th out of 1450 (Top 4%) in the private leaderboard, which is good enough to earn us a silver medal. However, we experienced a big slip up from the public leaderboard to the private leaderboard. Obviously we overfitted our predictions to the public leaderboard.
![]()
Lessons Learned
One of the great things about Kaggle is the strength of the community. For each competition, there is a separate forum where participating teams share scripts and bounce ideas off each other. The forum are usually very active and most participants are willing to share their insights unselfishly.
After the competition finished, many top teams shared their solutions in the forum. Below are some interesting ideas we learned from reading other teams’ approaches.
1. Use of other state-of-the-art models.
Most of the top teams use ResNet and Inception in their final ensemble. ResNet and Inception are more recently published and arguably more advanced models which surpass VGG in many of the performance benchmarks.
In particular, ResNet is the current state-of-the-art and winner of the ImageNet Challenge 2015. Almost all top teams include ResNet in their solutions. Some teams use only ResNet and was able to achieve very good result.
We did not use ResNet since it’s ImageNet pre-trained version in Keras was not available at that time (It’s available here now!). We did try out Inception model though but it somehow managed to get us a worse public leaderboard score, so we took it out of our final ensemble. In retrospect, adding inception model to our blend cause a jump of more than 10 positions in the private leaderboard! Overfitting to the public leaderboard certainly cost us dearly.
2. Establish a reliable local cross validation benchmark
One of the biggest mistakes we made is the failure to establish a reliable local cross validation (cv) benchmark. As a result, we had no choice but to overfit our prediction to the public leaderboard, which turned out to be a really bad idea. Half way through the competition we tried out Stack Generalization to ensemble our base models. It didn’t work out as expected, and led to our complete disregard of the local cv score in later part of the competition.
In fact, it’s not easy to establish a good local cv benchmark for this competition due to the nature of this dataset. There are too many images on too few drivers, and drivers appear in the training set won’t appear in the test set.
3. Image Preprocessing
The goal of this competition is to identify the drivers’ behavior in the car. That said, we should get our model to focus on the part of the image that contains the driver and cut out the useless part of the image, say, the rear part of the car that might add undesirable noise. Many top teams attempt to do exactly that using various methods including R-CNN and VGG-CAM. One top 10 teams even perform manual cropping on hundreds of images (himself!) and run bounding box regression on the rest of the images.
4. And the most important trick of all - K Nearest Neighbor
Though the dataset contains over 10,000 images in the train and test set combined, only less than 100 drivers were covered in the train and test set respectively. In fact, the individual images were discrete instances extracted from videos taken by the in-car camera. Hence, one can exploit the temporal dimension and reconstruct the sequences of images in time order. It turns out that images lined up that way are highly correlated to one another.
The top few teams managed to take advantage of this fact and perform K Nearest Neighbor (KNN) to group images into highly correlated clusters, and average the prediction of the closest neighbors to obtain the final prediction. According to the winner of the competition, KNN averaging alone accounts for 40% reduction of public leaderboard score!
Conclusion and Final Thoughts
This is my first serious attempt in Deep Learning and I am extremely grateful for the opportunity. Though the final slip up in the leaderboard did bring some level of disappointment, this is insignificant compare to the amount of learning and mental excitement that brought forth.
I think the contribution of the Kaggle competition to Deep Learning is definitely not in the modelling part. None of the teams invent new neural architectures for the sake of this competition. It’s more on the innovative tricks, hacks and techniques deployed in the data preprocessing and model ensembling parts, for example, VGG-CAM inference, manual cropping and bounding box regression, novel color jittering methods, etc, that worked well in practice but are seldom talked about or being completely overlooked by the academic community.
If you have any questions or thoughts feel free to leave a comment below.
You can also follow me on Twitter at @flyyufelix.