This is Part II of a 2 part series that cover fine-tuning deep learning models in Keras. Part I states the motivation and rationale behind fine-tuning and gives a brief introduction on the common practices and techniques. This post will give a detailed step-by-step guide on how to go about implementing fine-tuning on popular models VGG, Inception, and ResNet in Keras.
Why do we pick Keras?
Keras is a simple to use neural network library built on top of Theano or TensorFlow that allows developers to prototype ideas very quickly. Unless you are doing some cutting-edge research that involves customizing a completely novel neural architecture with different activation mechanism, Keras provides all the building blocks you need to build reasonably sophisticated neural networks.
It also comes with a great documentation and tons of online resources.
Note on Hardware
I would strongly suggest getting a GPU to do the heavy computation involved in Covnet training. The speed difference is very substantial. We are talking about a matter of hours with a GPU versus a matter of days with a CPU.
I would recommend GTX 980Ti or a slightly expensive GTX 1080 which cost around $600 bucks.
Fine-tuning in Keras
I have implemented starter scripts for fine-tuning convnets in Keras. The scripts are hosted in this github page. Implementations of VGG16, VGG19, GoogLeNet, Inception-V3, and ResNet50 are included. With that, you can customize the scripts for your own fine-tuning task.
Below is a detailed walkthrough of how to fine-tune VGG16 and Inception-V3 models using the scripts.
Fine-tune VGG16. VGG16 is a 16-layer Covnet used by the Visual Geometry Group (VGG) at Oxford University in the 2014 ILSVRC (ImageNet) competition. The model achieves a 7.5% top 5 error rate on the validation set, which is a result that earned them a second place finish in the competition.
Schematic Diagram of VGG16 Model:
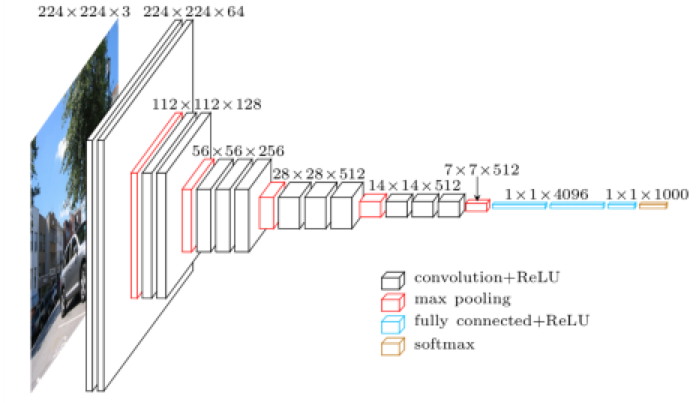
The script for fine-tuning VGG16 can be found in vgg16.py. The first part of the vgg_std16_model function is the model schema for VGG16. After defining the fully connected layer, we load the ImageNet pre-trained weight to the model by the following line:
model.load_weights('cache/vgg16_weights.h5')For fine-tuning purpose, we truncate the original softmax layer and replace it with our own by the following snippet:
model.layers.pop()
model.outputs = [model.layers[-1].output]
model.layers[-1].outbound_nodes = []
model.add(Dense(num_class, activation='softmax'))Where the num_class variable in the last line represents the number of class labels for our classification task.
Sometimes, we want to freeze the weight for the first few layers so that they remain intact throughout the fine-tuning process. Say we want to freeze the weights for the first 10 layers. This can be done by the following lines:
for layer in model.layers[:10]:
layer.trainable = FalseWe then fine-tune the model by minimizing the cross entropy loss function using stochastic gradient descent (sgd) algorithm. Notice that we use an initial learning rate of 0.001, which is smaller than the learning rate for training scratch model (usually 0.01).
sgd = SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
model = vgg_std16_model(img_rows, img_cols, channel, num_class)Where img_rows, img_cols, and channel define the dimension of the input. For colored image with resolution 224x224, img_rows = img_cols = 224, channel = 3.
Next, we load our dataset, split it into training and testing sets, and start fine-tuning the model:
X_train, X_valid, Y_train, Y_valid = load_data()
model.fit(train_data, test_data,
batch_size=batch_size,
nb_epoch=nb_epoch,
shuffle=True,
verbose=1,
validation_data=(X_valid, Y_valid),
)The fine-tuning process will take a while, depending on your hardware. After it is done, we use the model the make prediction on the validation set and return the score for the cross entropy loss:
predictions_valid = model.predict(X_valid, batch_size=batch_size, verbose=1)
score = log_loss(Y_valid, predictions_valid)Fine-tune Inception-V3. Inception-V3 achieved the second place in the 2015 ImageNet competition with a 5.6% top 5 error rate on the validation set. The model is characterized by the usage of the Inception Module, which is a concatenation of features maps generated by kernels of varying dimensions.
Schematic Diagram of the 27-layer Inception-V1 Model (Idea similar to that of V3):

The code for fine-tuning Inception-V3 can be found in inception_v3.py. The process is mostly similar to that of VGG16, with one subtle difference. Inception-V3 does not use Keras’ Sequential Model due to branch merging (for the inception module), hence we cannot simply use model.pop() to truncate the top layer.
Instead, after we create the model and load it up with the ImageNet weight, we perform the equivalent of top layer truncation by defining another fully connected sofmax (x_newfc) on top of the last inception module (x). This is done using the following snippet:
# Last Inception Module
x = merge([branch1x1, branch3x3, branch3x3dbl, branch_pool],
mode='concat', concat_axis=channel_axis,
name='mixed' + str(9 + i))
# Fully Connected Softmax Layer
x_fc = AveragePooling2D((8, 8), strides=(8, 8), name='avg_pool')(x)
x_fc = Flatten(name='flatten')(x_fc)
x_fc = Dense(1000, activation='softmax', name='predictions')(x_fc)
# Create model
model = Model(img_input, x_fc)
# Load ImageNet pre-trained data
model.load_weights('cache/inception_v3_weights_th_dim_ordering_th_kernels.h5')
# Truncate and replace softmax layer for transfer learning
# Cannot use model.layers.pop() since model is not of Sequential() type
# The method below works since pre-trained weights are stored in layers but not in the model
x_newfc = AveragePooling2D((8, 8), strides=(8, 8), name='avg_pool')(x)
x_newfc = Flatten(name='flatten')(x_newfc)
# Create another model with our customized softmax
model = Model(img_input, x_newfc)
# Learning rate is changed to 0.001
sgd = SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
model = inception_v3_model(img_rows, img_cols, channel, num_class)That’s it for Inception-V3. Starting script for other models such as VGG19, GoogleLeNet, and ResNet can be found here.
Fine-tuned Networks in Action
If you are a Deep Learning or Computer Vision practitioner, most likely you have already tried fine-tuning pre-trained network for your own classification problem before.
To me, I came across this interesting Kaggle Competition which requires candidates to identify distracted drivers through analyzing in-car camera images. This is a good opportunity for me to try out fine-tuning in Keras.
Following the fine-tuning methods listed above, together with data preprocessing/augmentation and model ensembling our team managed to achieved top 4% in the competition. Detailed account of our method and lessons learned are captured in this post.
If you have any questions or thoughts feel free to leave a comment below.
You can also follow me on Twitter at @flyyufelix.